知识检索¶
Note: ⚠️ 本文档由 AI 自动翻译。如有任何不准确之处,请参考英文原版。
简介¶
你可以通过知识检索节点将已有知识库集成到 Chatflow 或 Workflow 应用中。该节点在指定知识库中检索与查询相关的信息,并将检索结果作为上下文内容传递给下游节点(如 LLM)使用。
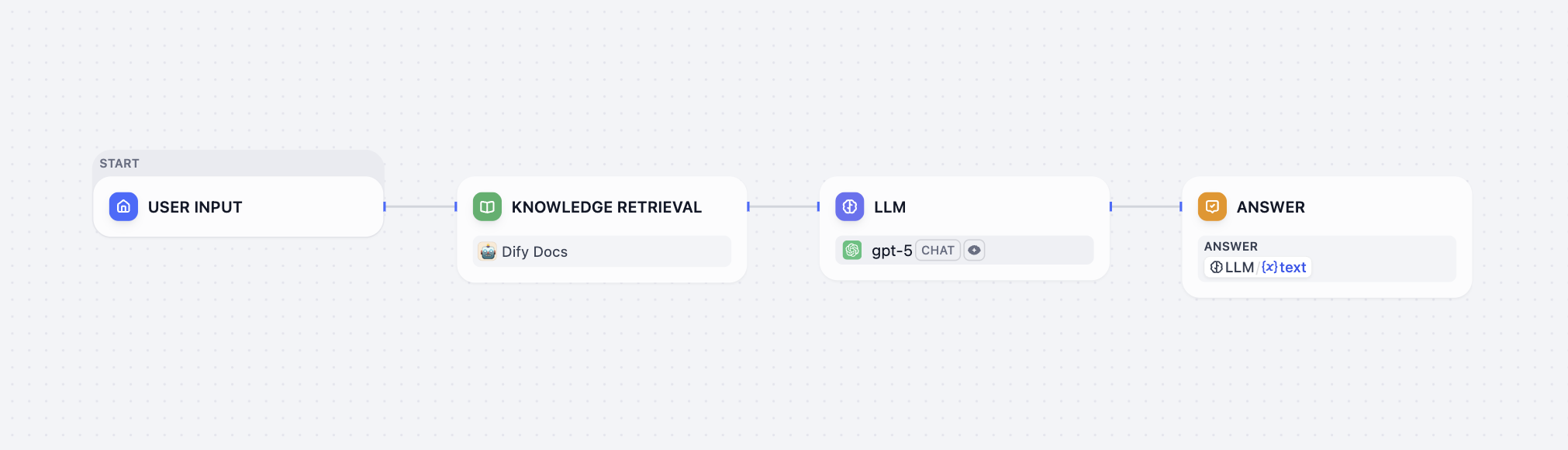
知识检索节点在 Chatflow 中的典型用例如下:
-
用户输入 节点收集用户问题。
-
知识检索 节点在指定知识库中检索与用户问题相关的内容,并输出检索结果。
-
LLM 节点基于用户问题和检索结果生成回复。
-
直接回答 节点将 LLM 的回复输出给用户。
Info:
使用知识检索节点前,确保至少有一个可用的知识库。了解如何创建知识库,阅读 [知识库](/zh/use-flexai/knowledge/readme#创建知识库)。Note:
在 FlexAI Cloud 上,知识检索操作受订阅计划的频率限制。详见 [知识库请求频率限制](/zh/use-flexai/knowledge/knowledge-request-rate-limit)。
配置知识检索节点¶
要使知识检索节点正常工作,你需要指定:
-
检索什么(查询内容)
-
在哪里检索(知识库)
-
如何处理检索结果(节点级检索设置)
你还可以利用文档元数据实现基于筛选的检索,进一步提升检索精度。
指定查询内容¶
设置节点需要在指定知识库中检索的查询内容。
-
查询文本:选择一个文本变量。例如,在 Chatflow 中可用
userinput.query引用用户输入,而在 Workflow 中则可选择文本类型的用户输入变量。 -
查询图片:选择一个图片变量(如用户通过用户输入节点上传的图片),通过图片进行检索。图片大小限制为 2 MB。
Tip:
对于自托管部署,可通过环境变量 `ATTACHMENT_IMAGE_FILE_SIZE_LIMIT` 调整图片大小限制。Info:
当添加了至少一个多模态知识库时,才会出现 **查询图片** 选项。
此类知识库会带有 **Vision** 图标,表示其使用的是多模态嵌入模型。
选择检索的知识库¶
为节点添加一个或多个知识库,用于检索与查询内容相关的信息。
添加了多个知识库时,会同时检索所有知识库,合并结果并根据 节点级检索设置 进行处理。
Info:
带有 Vision 图标的知识库支持跨模态检索——基于语义相关性同时检索文本和图片。
Tip:
点击已添加知识库对应的 **编辑** 图标,可直接在知识检索节点内修改其设置。了解更多设置说明,阅读 [调整知识库设置](/zh/use-flexai/knowledge/manage-knowledge/introduction)。
调整节点级检索设置¶
设置节点在获取知识库检索结果后的处理方式。
Info:
检索设置分为知识库级和节点级两层。
可将其理解为先后两道筛选:知识库设置决定初步的检索结果池,而节点设置对结果进行重排序(Rerank)或进一步筛选。
-
Rerank 设置
- 权重设置:语义相似度与关键词匹配的权重。语义权重高则更注重语义相关性,关键词权重高则更偏向精确匹配。
Info:
仅当所有已添加的知识库使用的索引方式均为高质量时,才会出现 **权重设置** 的选项。
- **Rerank 模型**:根据与查询内容的相关性,对所有结果的相似度分数进行重新评定和排序。
Note:
若添加了多模态知识库,需同时选择多模态 Rerank 模型(带有 **Vision** 图标)。否则,检索到的图片将在重排序和最终输出中被排除。
-
Top K:重排序后返回的最大结果数。选择 Rerank 模型时,该值将根据模型的最大输入容量自动调整。
-
Score 阈值:返回结果的最低相似度分数。低于该阈值的结果会被过滤。阈值高表示对结果的相关性更严格,阈值低则更宽松。
启用元数据过滤¶
可利用已有的文档元数据,将检索范围限定在知识库的特定文档内,以进一步提升检索精度。
启用元数据过滤后,知识检索节点仅会检索符合指定元数据过滤条件的文档,而非整个知识库。尤其适用于内容多样的大型知识库。
Info:
了解如何创建与管理文档元数据,阅读 [元数据](/zh/use-flexai/knowledge/metadata)。
输出变量¶
知识检索节点将检索结果输出为 result 变量——一个包含分段内容、元数据、标题等属性的文档分段数组。
若检索结果中包含图片附件,result 变量中将增加包含图片元数据的 files 字段。
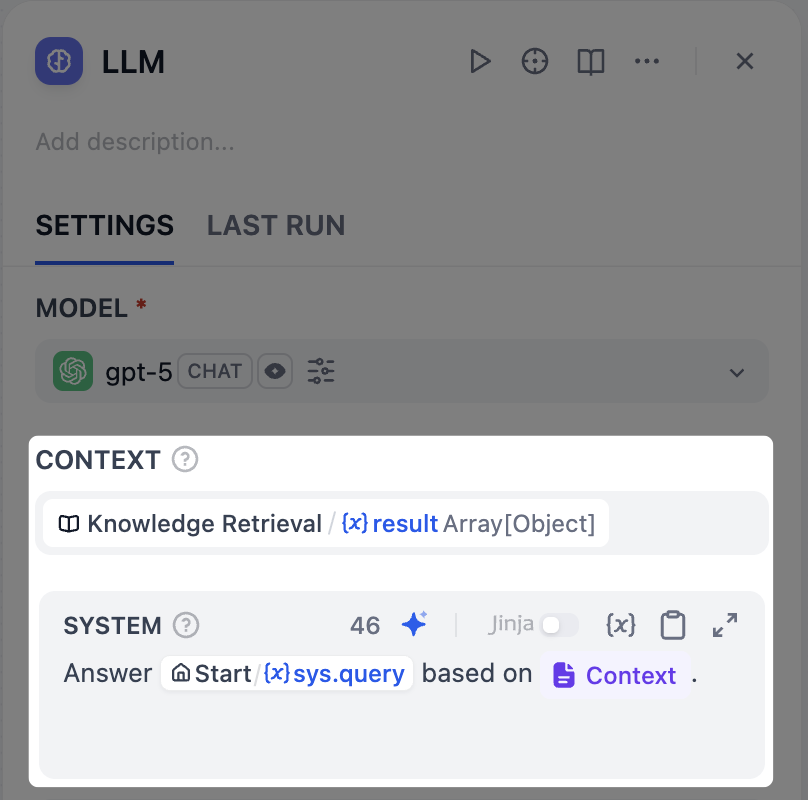
搭配 LLM 节点使用知识检索节点¶
如需在 LLM 节点中基于检索结果回答用户问题:
-
在 上下文 字段中,选择知识检索节点的
result变量。 -
在提示词字段中,同时引用
上下文变量和用户输入变量(如 Chatflow 中的userinput.query)。 -
(可选)若 LLM 支持视觉能力(带有 Vision 图标),可启用 Vision,以便其理解检索到的图片。
Info:
启用 **Vision** 后,LLM 会自动处理检索到的图片。无需在 **Vision** 输入字段中再次手动引用 `上下文` 变量。