モデルプロバイダー¶
Note: ⚠️ このドキュメントはAIによって自動翻訳されています。不正確な部分がある場合は、英語版を参照してください。
モデルプロバイダーは、ワークスペースにAIモデルへのアクセスを提供します。構築するすべてのアプリケーションには動作するためのモデルが必要であり、ワークスペースレベルでプロバイダーを設定することで、すべてのチームメンバーがすべてのプロジェクトでモデルを使用できます。
システムプロバイダー vs カスタムプロバイダー¶
システムプロバイダーはFlexAIによって管理されます。セットアップなしでモデルに即座にアクセスでき、FlexAIサブスクリプションを通じて請求され、新しいモデルが利用可能になると自動的に更新されます。迅速に開始するのに最適です。
カスタムプロバイダーは、OpenAI、Anthropic、Googleなどのモデルプロバイダーに直接アクセスするために独自のAPIキーを使用します。完全な制御、直接請求、多くの場合より高いレート制限を得られます。本番アプリケーションに最適です。
両方を同時に使用できます—プロトタイピングにはシステムプロバイダー、本番にはカスタムプロバイダーを使用できます。
カスタムプロバイダーの設定¶
ワークスペースの管理者とオーナーのみがモデルプロバイダーを設定できます。プロセスはプロバイダー間で一貫しています:
設定 → モデルプロバイダーに移動¶
ワークスペース設定でモデルプロバイダー設定にアクセスします。
プロバイダーを選択¶
OpenAI、Anthropic、Google、Cohere、またはその他のサポートされているプロバイダーから選択します。
認証情報を追加¶
APIキーとプロバイダーが必要とするその他の設定を入力します。
テストして保存¶
FlexAIはプロバイダーをワークスペースで利用可能にする前に認証情報を検証します。
サポートされているプロバイダー¶
大規模言語モデル:
- OpenAI (GPT-4, GPT-3.5-turbo)
- Anthropic (Claude)
- Google (Gemini)
- Cohere
- Ollama経由のローカルモデル
埋め込みモデル: - OpenAI Embeddings - Cohere Embeddings - Azure OpenAI - ローカル埋め込みモデル
専用モデル: - 画像生成 (DALL-E, Stable Diffusion) - 音声 (Whisper, ElevenLabs) - モデレーションAPI
プロバイダー設定例¶
OpenAI:
**必須:** OpenAI PlatformのAPIキー
**オプション:** Azure OpenAIまたはプロキシ用のカスタムベースURL、組織スコープ使用のための組織ID
**利用可能なモデル:** GPT-4, GPT-3.5-turbo, DALL-E, Whisper, テキスト埋め込み
Anthropic:
**必須:** Anthropic ConsoleのAPIキー
**利用可能なモデル:** Claude 3 (Opus, Sonnet, Haiku), Claude 2.1, Claude Instant
ローカル (Ollama):
**必須:** OllamaサーバーURL (通常は http://localhost:11434)
**セットアップ:** Ollamaをインストール、モデルをプル (`ollama pull llama2`)、FlexAI接続を設定
**メリット:** 完全なデータプライバシー、外部API費用なし、カスタムモデルファインチューニング
モデルの認証情報を管理¶
モデルプロバイダーの定義済みモデルやカスタムモデルに対して、複数の認証情報を追加し、それらの認証情報の切り替え、削除、変更を簡単に行うことができます。
以下のシナリオでは、複数のモデル認証情報を追加することをお勧めします。
-
環境の分離: 開発、テスト、本番など、環境ごとに別々のモデル認証情報を設定します。例えば、開発環境ではデバッグ用にレート制限のある認証情報を使用し、本番環境ではサービスの品質を確保するために、安定したパフォーマンスと十分なクォータを持つ有料の認証情報を使用します。
-
コストの最適化: 異なるアカウントやモデルプロバイダーから複数の認証情報を追加して切り替えることで、無料または低コストのクォータを最大限に活用し、アプリケーションの開発・運用コストを削減します。
-
モデルのテスト: モデルのファインチューニングやイテレーションの過程で、複数のモデルバージョンを作成することがあります。これらの異なるバージョンの認証情報を追加することで、素早く切り替えてパフォーマンスのテストや評価を行うことができます。
Tip:
複数の認証情報を使用して、モデルのロードバランシングを設定することもできます。
定義済みモデル:
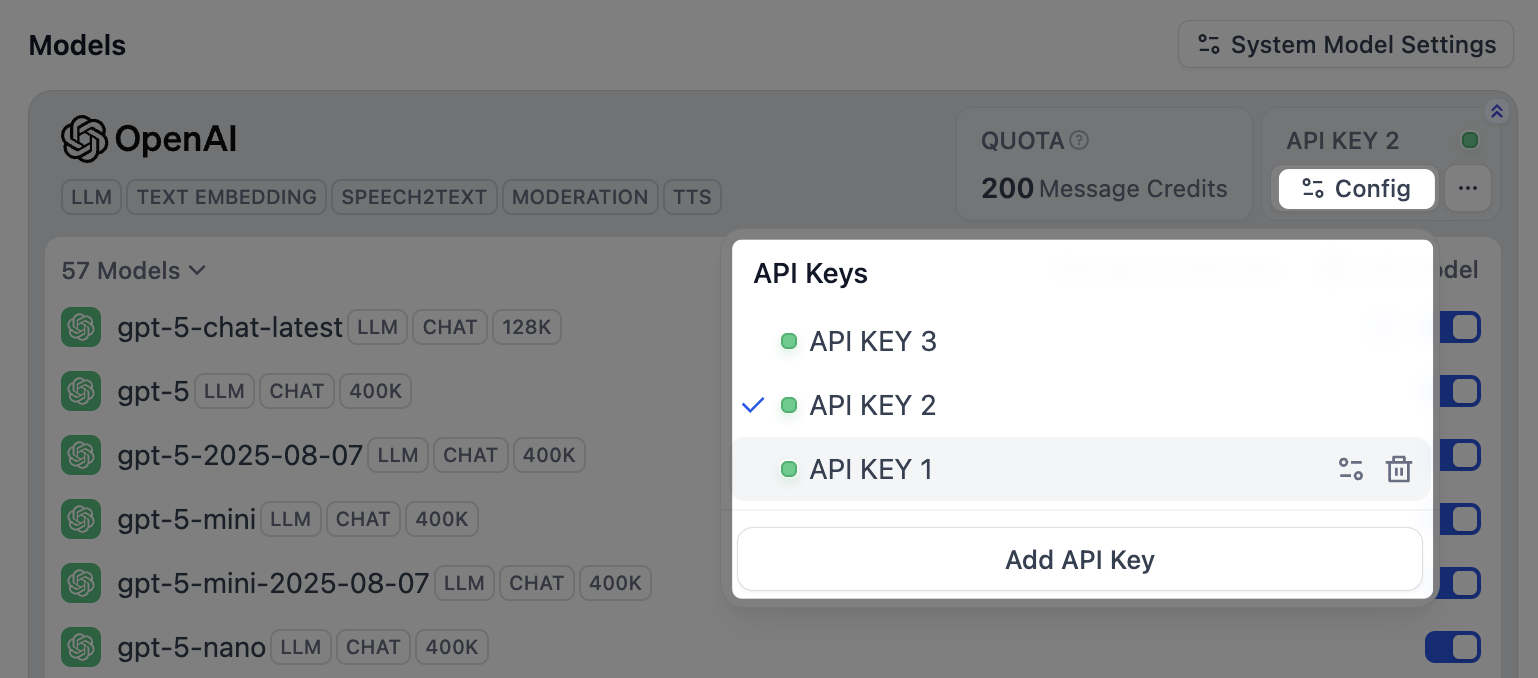
モデルプロバイダーをインストールして最初の認証情報を設定した後、右上の **コンフィグ** をクリックして、以下の操作を実行します。
- 新しい認証情報を追加する
- すべての定義済みモデルのデフォルトとして認証情報を選択する
- 認証情報を編集する
- 認証情報を削除する
Note:
デフォルトの認証情報を削除した場合は、手動で新しい認証情報を指定する必要があります。
カスタムモデル:
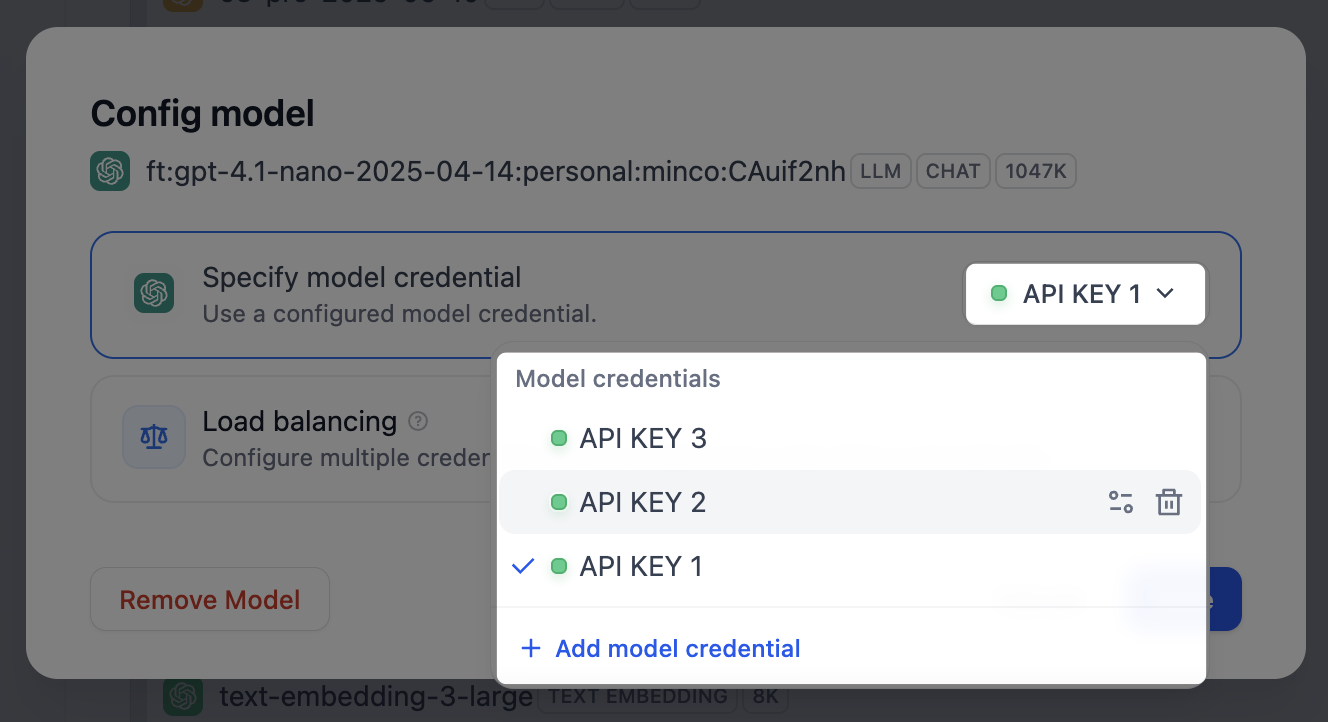
### 個別のカスタムモデルの認証情報を管理する
モデルプロバイダーをインストールし、カスタムモデルを追加したら、以下の手順に従います。
1. モデルリストで、対応する **コンフィグ** をクリックします。
2. **モデルの資格情報を指定してください** パネルで、デフォルトの認証情報をクリックして認証情報リストを開き、次の操作を行います。
- 新しい認証情報を追加する
- 認証情報をそのカスタムモデルのデフォルトとして選択する
- 認証情報を編集する
- 認証情報を削除する
Warning:
カスタムモデルの唯一の認証情報を削除すると、そのモデルも削除されます。
Info:
既存のカスタムモデルと名前およびタイプが同一の新しいカスタムモデルを追加しようとすると、システムは重複したモデルを作成する代わりに、その既存モデルに新しい認証情報を追加します。
### すべてのカスタムモデルの認証情報を管理する
**Manage Credentials** をクリックすると、すべてのカスタムモデルの認証情報を表示、編集、または削除できます。
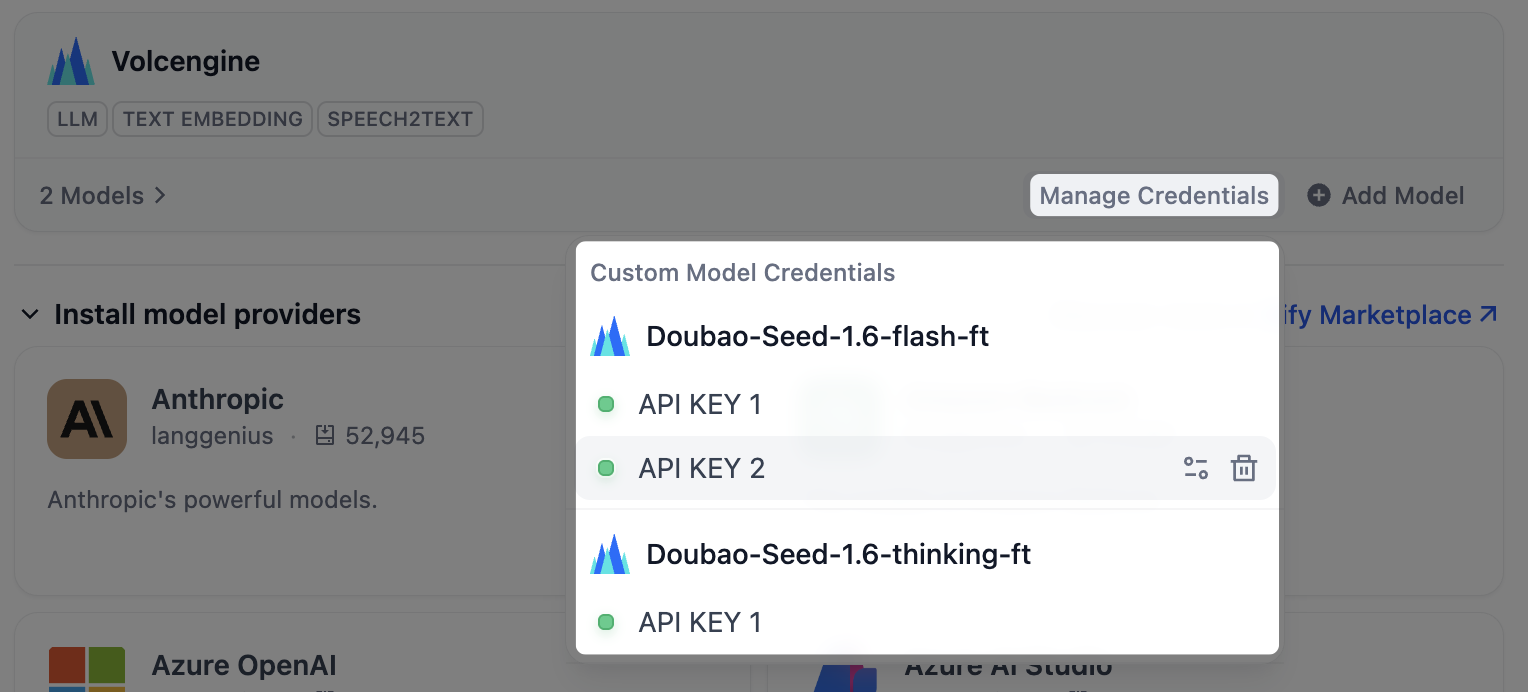
カスタムモデルを削除した後も、その認証情報は **Manage Credentials** リストに残ります。**モデルの追加** をクリックすると、認証情報が残っている削除済みのカスタムモデルがすべて表示され、それらをすばやく再追加できます。
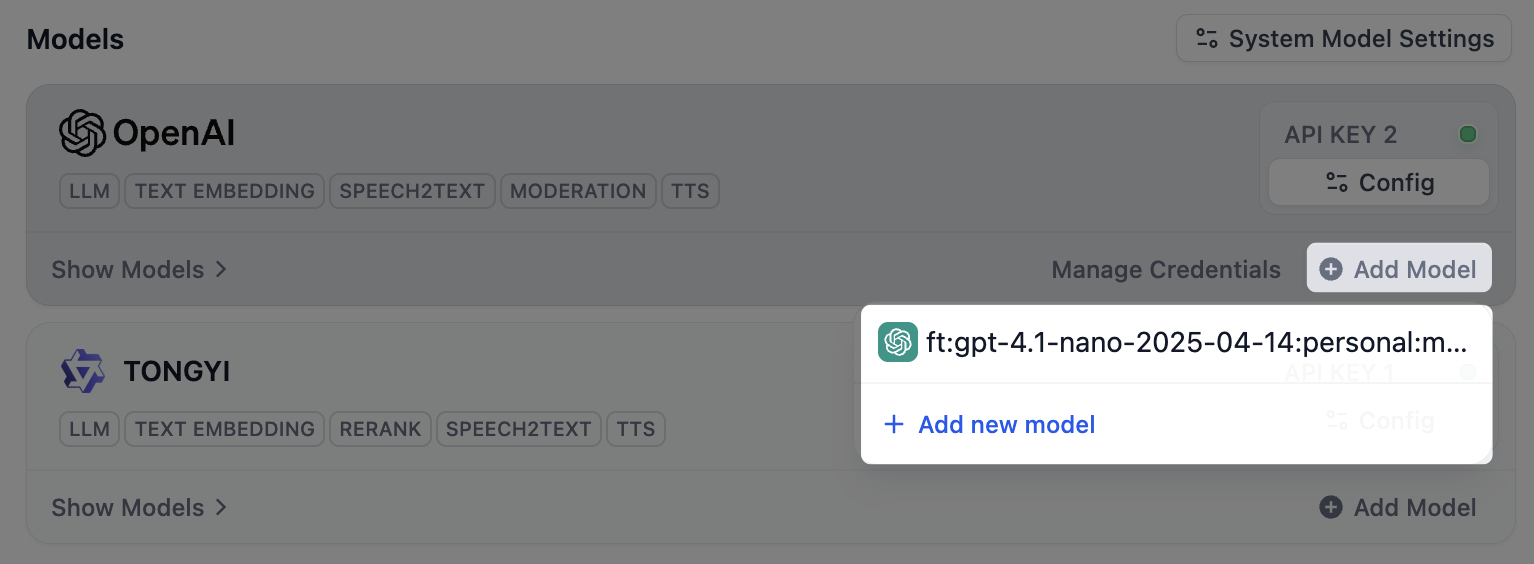
削除したカスタムモデルの認証情報をすべて **Manage Credentials** リストから削除した場合、そのモデルは **モデルの追加** をクリックしても表示されなくなります。
モデルのロードバランシングを設定¶
Info:
ロードバランシングは有料機能です。SaaS有料プランのサブスクリプションまたはエンタープライズ版の購入によって有効化できます。
モデルプロバイダーは通常、安定性と公平な利用を確保するため、特定の時間枠内でのAPIアクセスにレート制限を設けています。エンタープライズアプリケーションでは、単一の認証情報に対して大量の同時リクエストが発生すると、この制限に容易に達してしまい、ユーザーアクセスが中断される可能性があります。
効果的な解決策はロードバランシングです。これは、リクエストのトラフィックを複数のモデル認証情報に分散させる手法です。これにより、レート制限の問題や単一障害点を回避し、ビジネスの継続性を確保するとともに、すべてのユーザーに対してより速い応答時間を実現します。
FlexAIはロードバランシングにラウンドロビン方式を採用しており、モデルへのリクエストをロードバランシングプール内の各認証情報に順番にルーティングします。ある認証情報がレート制限に達した場合、無駄な再試行を避けるために、その認証情報は1分間、ローテーションから一時的に除外されます。
モデルのロードバランシングを設定するには、次の手順に従います。
-
モデルリストで対象のモデルを探し、対応する コンフィグ をクリックして 負荷分散 を選択します。
-
ロードバランシングプールで 認証情報を追加する をクリックし、既存の認証情報を選択するか、新しい認証情報を追加します。
Info:
**デフォルトの設定** は、そのモデルに現在指定されているデフォルトの認証情報を指します。Tip:
特定の認証情報がより高いクォータを持つ、またはより優れたパフォーマンスを示す場合は、その認証情報を複数回追加することでロードバランシングにおける重みを増し、より多くのリクエストを処理させることができます。
<img src="/images/add_load_balancing_credential.png" alt="Add credentials for load balancing" width="400" />
-
負荷分散プールで少なくとも2つの認証情報を有効にし、保存 をクリックします。負荷分散が有効になったモデルには、特別なアイコンが表示されます。

Info:
ロード バランシング モードからデフォルトの単一認証情報モードに戻しても、ロード バランシングの設定は将来の使用のために保持されます。
アクセスと請求¶
システムプロバイダーはFlexAIサブスクリプションを通じて請求され、プランに基づく使用制限があります。カスタムプロバイダーはプロバイダー(OpenAI、Anthropicなど)を通じて直接請求され、多くの場合より高いレート制限を提供します。
チームアクセスはワークスペース権限に従います: - オーナー/管理者はプロバイダーを設定、修正、削除できます - エディター/メンバーは利用可能なプロバイダーを表示し、アプリケーションで使用できます
Warning:
APIキーは安全に保存されますが、ワークスペース全体のモデルアクセスを許可します。請求責任を負うべき信頼できるチームメンバーにのみ管理者権限を与えてください。
トラブルシューティング¶
認証失敗: APIキーの正確性を確認し、有効期限をチェックし、十分なクレジットがあることを確認し、キーの権限を確認してください。
モデルが利用できない: プロバイダー設定にモデルが含まれていることを確認し、APIキーのティアアクセスを確認し、プロバイダー設定を更新してください。
レート制限: プロバイダーアカウントをアップグレードし、リクエストキューイングを実装し、より高い制限のためにカスタムプロバイダーを検討してください。