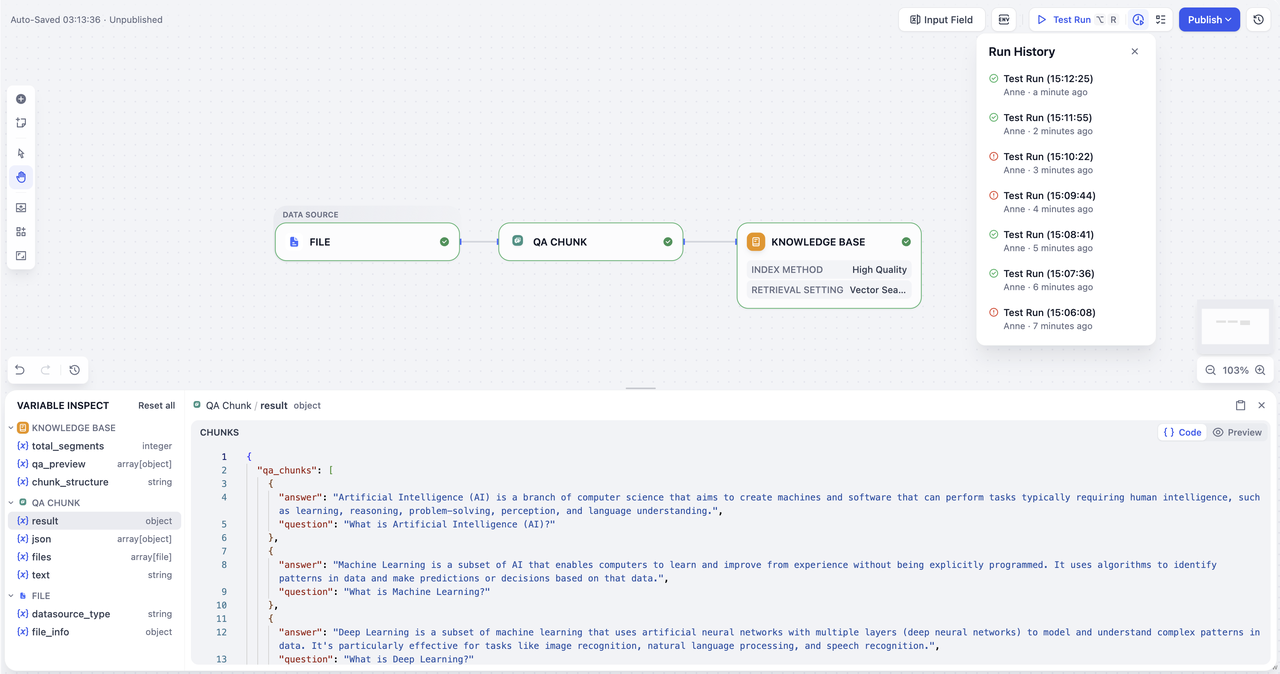
ステップ2:ナレッジパイプラインのオーケストレーション¶
ナレッジパイプラインの構築¶
工場の生産ラインを例に考えてみましょう。各ステーション(ノード)が特定の作業を担当し、それらを連携させて部品を組み立て、最終製品を完成させます。ナレッジパイプラインの構築も同様のプロセスです。視覚的なワークフロー設計ツールを使用し、ドラッグ&ドロップ操作だけで容易にデータ処理の流れを設計できます。これにより、ドキュメントの取り込み、処理、分割、インデックス化、検索戦略を自在に管理できます。
本ステップでは、ナレッジパイプライン全体のプロセス、各ノードの役割や設定方法について学び、独自のデータ処理フローをカスタマイズして、効率的にナレッジベースを管理・最適化する方法を解説します。
インターフェースの状態¶
オーケストレーションキャンバスに入ると、次の状態を確認できます。 - タブの状態: 「Documents(ドキュメント)」「Retrieval Test(検索テスト)」「Settings(設定)」タブはグレーアウトされ利用不可です。 - 必要ステップ:パイプラインのオーケストレーションと公開が完了しないと、ファイルアップロードやその他機能は利用できません。
選択したテンプレートによって、初期画面の表示が異なります。
空白ナレッジベースパイプラインを選択した場合は、ナレッジベースノードだけが配置されたキャンバスが表示され、ノード横のガイドの指示に従って作成を進めます。
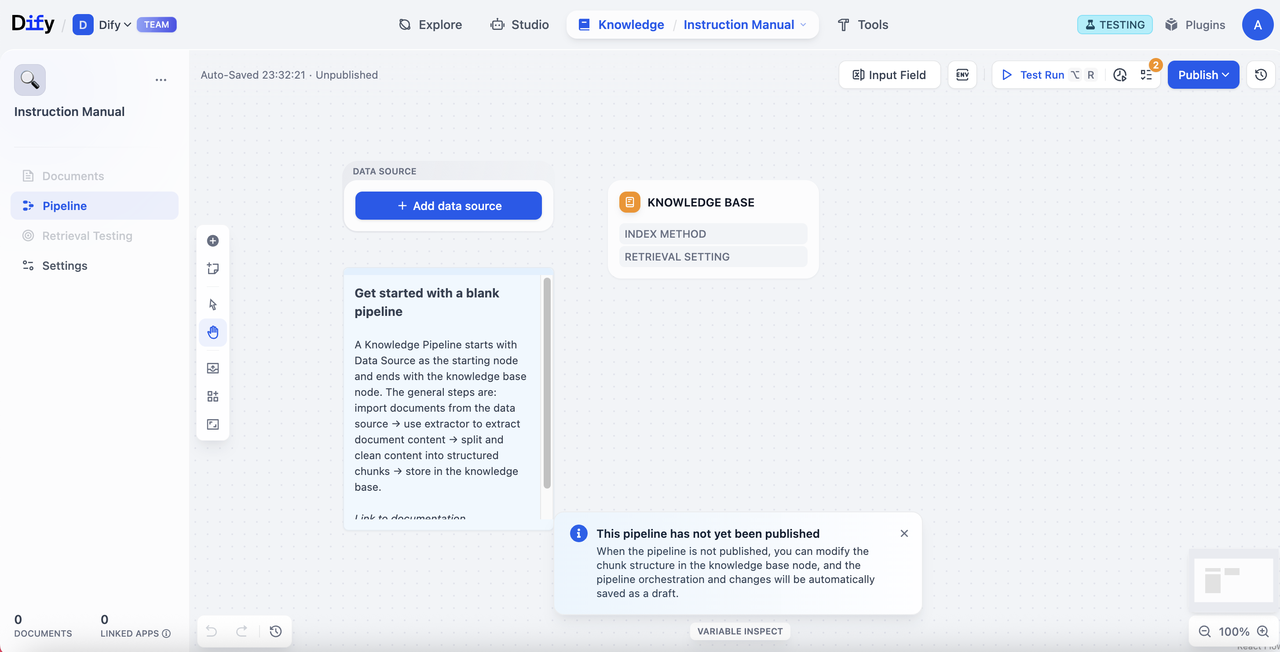
特定のパイプラインテンプレートを選択した場合は、あらかじめワークフローが組まれた状態でキャンバスに表示され、すぐに利用・編集が可能です。
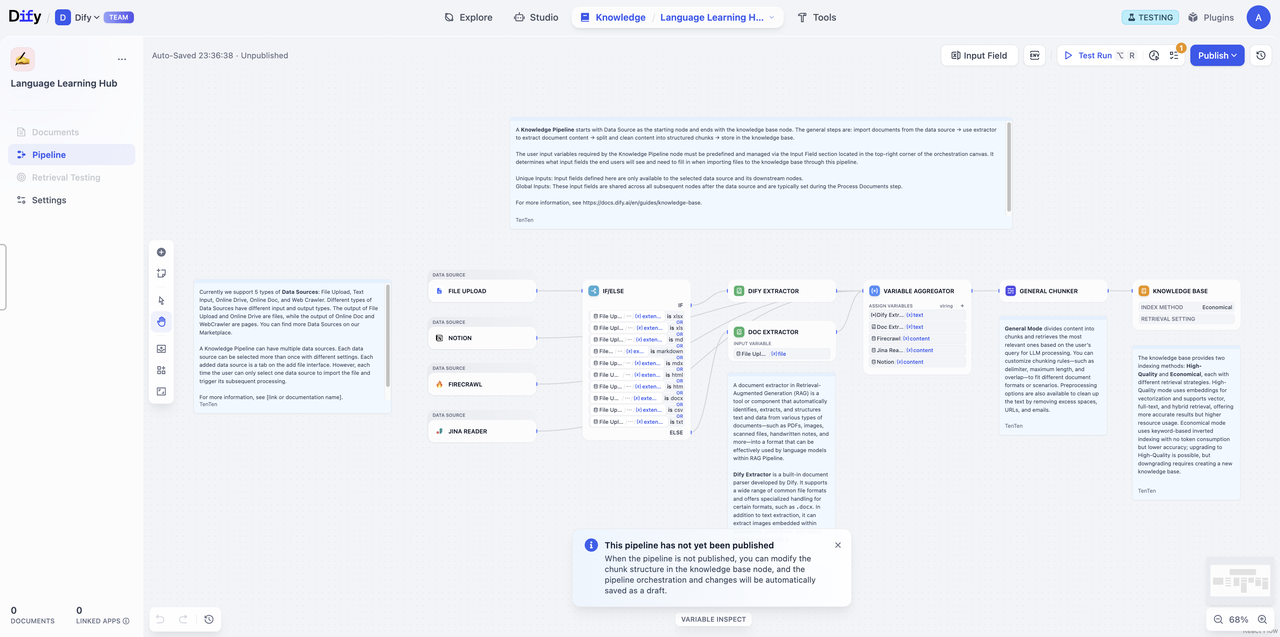
ナレッジパイプラインの全体プロセス¶
まず、ナレッジパイプラインにおける処理プロセスを分解し、ドキュメントがどのように検索可能なナレッジベースへと変換されるのかを理解しましょう。
ナレッジパイプラインは、以下の主要なステップから構成されます:
Tip:
データソース → データ処理(抽出器+分割器)→ ナレッジベースノード(分割構造+検索設定)→ ユーザー入力フォーム → テスト&公開
- データソース:さまざまな情報源(ローカルファイル、Notion、Webページなど)からのコンテンツ
- データ処理:データ内容の加工と変換
- 抽出器(Extractor):ドキュメントの解析・構造化
- 分割器(Chunker):構造化された内容を扱いやすい断片に分割
- ナレッジベース:分割構造と検索設定の構築
- ユーザー入力フォーム:ユーザーがパイプライン実行時に必要なパラメータや情報を入力するための定義
- テスト&公開:設定の検証および運用開始
ステップ1:データソースの設定¶
ナレッジベースには、単一または複数のデータソースを選択できます。現在、FlexAIでは主に4種類のデータソースをサポートしています:ファイルアップロード、クラウドストレージ、オンラインドキュメント、Webクローラー。
さらに多様なデータソースについては、FlexAI Marketplaceをご参照ください。
ファイルアップロード¶
ローカルファイルはドラッグ&ドロップまたはファイル選択でアップロードできます。
オンラインドキュメント¶
Notion¶
Notionワークスペースと連携し、ページやデータベースをシームレスにインポート可能です。ナレッジベースは常に自動で最新状態に保たれます。
Webクローラー¶
Webコンテンツを大規模言語モデルでも読みやすい形式に変換します。ナレッジベースはJina ReaderとFirecrawlをサポートしています。
Jina Reader¶
シンプルかつ使いやすいAPIを提供するオープンソースのWeb解析ツールです。Webコンテンツの高速クロールと処理に適しています。
Firecrawl¶
きめ細かなクロール制御オプションとAPIサービスを持つオープンソースのWeb解析ツールです。複雑なサイトの深層クロールやバッチ処理に適しています。
クラウドストレージ¶
Google Drive、Dropbox、OneDriveなどのクラウドストレージサービスと連携し、FlexAIが自動でファイルを取得します。選択したドキュメントをインポートするだけなので、事前の手動ダウンロードは不要です。
Tip:
認証に関するサポートが必要な場合は、データソース認証ガイドをご参照ください。
ステップ2:データ処理ツールの設定¶
このステップでは、コンテンツの抽出、分割、最適なナレッジベース用フォーマットへの変換を行います。これは、料理でいう「食材の下準備」と同じく、後に素早く加工できる状態を整える工程です。
ドキュメントプロセッサ¶
PDF, XLSX, DOCXなど多様な形式のドキュメントが存在しますが、LLMはこれらをそのまま扱えません。そのため、抽出器(Extractor)が各種ファイルを解析・変換し、LLMが扱いやすい形式に変換します。
FlexAIのドキュメント抽出器、あるいはMarketplaceから「FlexAI Extractor」「Unstructured」等のツールを選択できます。
Doc Extractor(ドキュメント抽出器)¶

情報処理の中核となり、入力ファイルを識別・読取・情報抽出を行い、次のノードで利用できる形式へ変換します。
Tip:
詳細はドキュメント抽出器をご参照ください。
FlexAI Extractor¶
FlexAI Extractorは、FlexAIが提供する内蔵ドキュメント解析ツールです。一般的なファイル形式に幅広く対応し、特にDocファイルに最適化されています。画像抽出・保存や、画像URL返却も可能です。

Unstructured¶
Tip:
他のツールについてはFlexAI Marketplaceをご覧ください。
分割器(Chunker)¶
人間が一度に多くの情報を集中して理解できないように、LLMも大量情報の同時処理が苦手です。そのため、分割器は抽出後のドキュメントを小さな「チャンク」と呼ばれる断片に分割します。
用途やドキュメントの種類に応じ、最適な分割戦略が異なります。たとえば製品マニュアルは機能ごと、論文は論理セクションごとが理想的です。FlexAIでは主に3種類の分割器を用意しています。
分割器の種類概要¶
| 分割器タイプ | 特徴 | 最適用途 |
|---|---|---|
| 汎用分割器 | 固定サイズ分割、区切り文字のカスタマイズ可能 | シンプルなドキュメント |
| 親子分割器 | 二層構造:マッチング精度+豊富なコンテキスト | コンテキスト保持必須な複雑文書 |
| Q&Aプロセッサ | スプレッドシートのQ&Aペア処理 | 構造化Q&Aデータ(CSV/Excel等) |
共通テキスト前処理ルール¶
すべての分割器で利用できるテキストクリーニングオプション:
| オプション | 説明 |
|---|---|
| 連続空白・改行・タブの統一 | 連続する空白文字を単一空白へ変換 |
| URL・メールアドレスの削除 | Webリンクやメールアドレスを自動検出し削除 |
汎用分割器(General Chunker)¶
シンプルな構造の文書向けの基本的な分割モジュールです。テキスト分割や前処理オプションを柔軟にカスタマイズ可能です。
入力と出力変数
| タイプ | 変数 | 説明 |
|---|---|---|
| 入力変数 | {x} Content |
分割対象となる文書コンテンツ |
| 出力変数 | {x} Array[Chunk] |
分割済みコンテンツ配列(各要素は検索・分析向け) |
分割設定
| 設定項目 | 説明 |
|---|---|
| 区切り文字 | デフォルトは\n(段落区切り用改行)。正規表現も利用可。 |
| 最大チャンク長 | 各セグメントの最大文字数(上限超過時は自動分割) |
| チャンク重複 | 分割時にセグメント間で部分重複させることで情報保持・検索精度を向上 |
親子分割器(Parent-child Chunker)¶
クエリマッチング精度と豊富なコンテキスト両立のため、二層チャンク構造を採用しています。
親子分割器の仕組み
- 子チャンク(高精度マッチング用):通常、1文ごとの細かなセグメント
- 親チャンク(豊富なコンテキスト):該当する子チャンクを含む広い範囲(段落やセクション単位)
| タイプ | 変数 | 説明 |
|---|---|---|
| 入力変数 | {x} Content |
原文テキスト |
| 出力変数 | {x} Array[ParentChunk] |
親チャンク配列 |
分割設定
| 設定項目 | 説明 |
|---|---|
| 親チャンク区切り文字 | 親チャンクの分割ルール設定 |
| 親チャンク最大長 | 親チャンクの最大文字数 |
| 子チャンク区切り文字 | 子チャンク分割ルール |
| 子チャンク最大長 | 子チャンクの最大文字数 |
| 親モード | 「段落」または「全文書」いずれか選択 |
Q&Aプロセッサ¶
抽出&分割を1ノードで実施。FAQやQ&Aペアをテーブルとして持つCSV/Excelファイル専用です。
入出力変数
| タイプ | 変数 | 説明 |
|---|---|---|
| 入力変数 | {x} Document |
単一ファイル |
| 出力変数 | {x} Array[QAChunk] |
Q&Aチャンク配列 |
変数設定
| 設定項目 | 説明 |
|---|---|
| 質問用カラム番号 | 質問内容の列番号 |
| 回答用カラム番号 | 回答内容の列番号 |
ステップ3:ナレッジベースノードの設定¶
ドキュメントの処理・分割が完了したら、保存や検索の方法を設定します。ここでは、インデックス作成方法や検索戦略を用途に応じて選択可能です。
本ノードの設定項目は、入力変数、チャンク構造、インデックス方式、検索設定となります。
チャンク構造¶
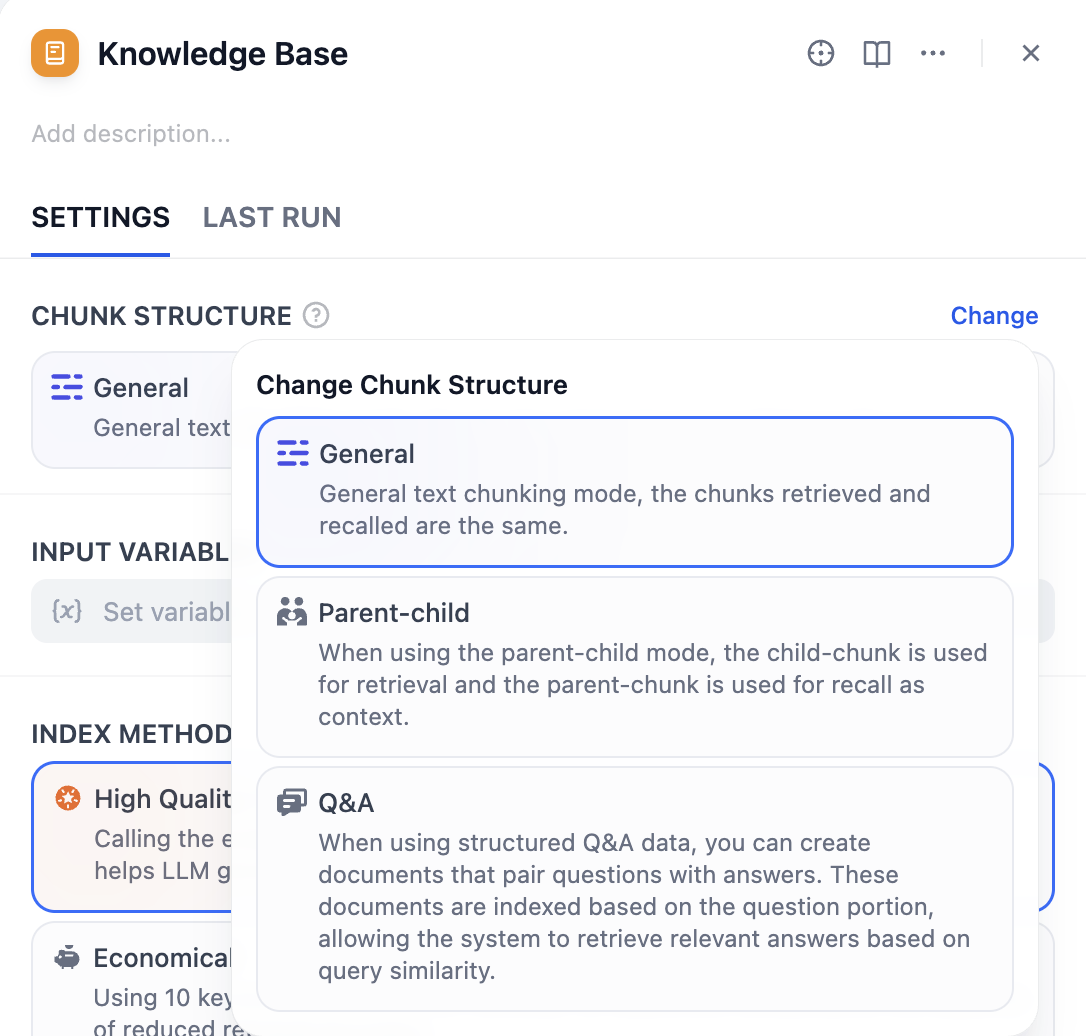
チャンク構造は、ナレッジベースが文書コンテンツをどう整理・インデックス化するかを定めます。用途やコストに適したモードを選択してください。
ナレッジベースは3つのチャンクモードをサポートします:汎用モード、親子モード、Q&Aモード。初めて設定する場合は親子モードが推奨されます。
Warning:
重要: チャンク構造は一度保存・公開すると変更できません。慎重にご選択ください。
汎用モード¶
標準的なドキュメント処理に最適です。ニーズに応じ、柔軟なインデックスと検索設定が選択可能です。
親子モード¶
検索時の高精度マッチングと文脈提供が必要なエンタープライズ向け専門ドキュメントに最適です。HQ(高品質)インデックスのみ対応です。
Q&Aモード¶
構造化された質問回答データ向けです。Q&Aペアが質問部に基づいてインデックス化され、関連回答が検索できます。こちらもHQモードのみ対応です。
入力変数¶
入力変数はデータ処理ノードからの出力をナレッジベースのデータソースとして受け取ります。分割器の出力をナレッジベースノードへ接続します。
- 汎用モード:
{x} Array[Chunk](汎用チャンク配列) - 親子モード:
{x} Array[ParentChunk](親チャンク配列) - Q&Aモード:
{x} Array[QAChunk](Q&Aチャンク配列)
インデックス方法と検索設定¶
インデックス方法はナレッジベース内のコンテンツ整理法を決定し、検索設定はそれに基づいた検索戦略を指定します。 ナレッジベースでは高品質とコスト効率の2方式があり、それぞれ検索方法が異なります。
高品質モードでは、埋め込みモデル(Embedding)によりテキストをベクトル化し、意味的な関連性検索が可能です(完全一致でなくても適切な回答に辿り着けます)。
コスト効率モードでは、各ブロックは10個のキーワードでインデックス化され、埋め込みモデルのコストは発生しません。
Tip:
詳細はインデックス方法と検索設定の選択もご参照ください。
インデックス方法と検索設定概要¶
| インデックス方法 | 検索設定 | 説明 |
|---|---|---|
| 高品質 | ベクトル検索 | 意味的類似性(自然言語での深い検索) |
| 全文検索 | キーワードベースの包括的検索 | |
| ハイブリッド検索 | 意味検索+キーワード検索の組合せ | |
| コスト効率 | 逆引きインデックス | 一般的な検索エンジン型方式 |
詳細は以下の表をご参照ください。
| チャンク構造 | インデックス方法 | パラメータ | 検索設定 |
|---|---|---|---|
| 汎用モード | 高品質 コスト効率 |
埋め込みモデル キーワード数 |
ベクトル 全文 ハイブリッド検索 逆引きインデックス |
| 親子モード | 高品質のみ | 埋め込みモデル | ベクトル 全文 ハイブリッド検索 |
| Q&Aモード | 高品質のみ | 埋め込みモデル | ベクトル 全文 ハイブリッド検索 |
ステップ4:ユーザー入力フォームの作成¶
ユーザー入力フォームは、パイプライン実行時に必要な初期情報をユーザーから収集します。ワークフローの開始ノードと同様に、必要な设置情報(アップロードファイル、特定パラメータなど)を収集し、パイプラインの柔軟性・利便性を高めます。
フォームの作成方法¶
- パイプライン構築UI
-
「入力フィールド」をクリックして作成・設定を開始

-
ノードパラメータパネル
- ノード選択後、パラメータ入力欄の「+ ユーザー入力を作成」をクリック
ユーザー入力フィールドの追加¶
各エントランス固有入力¶
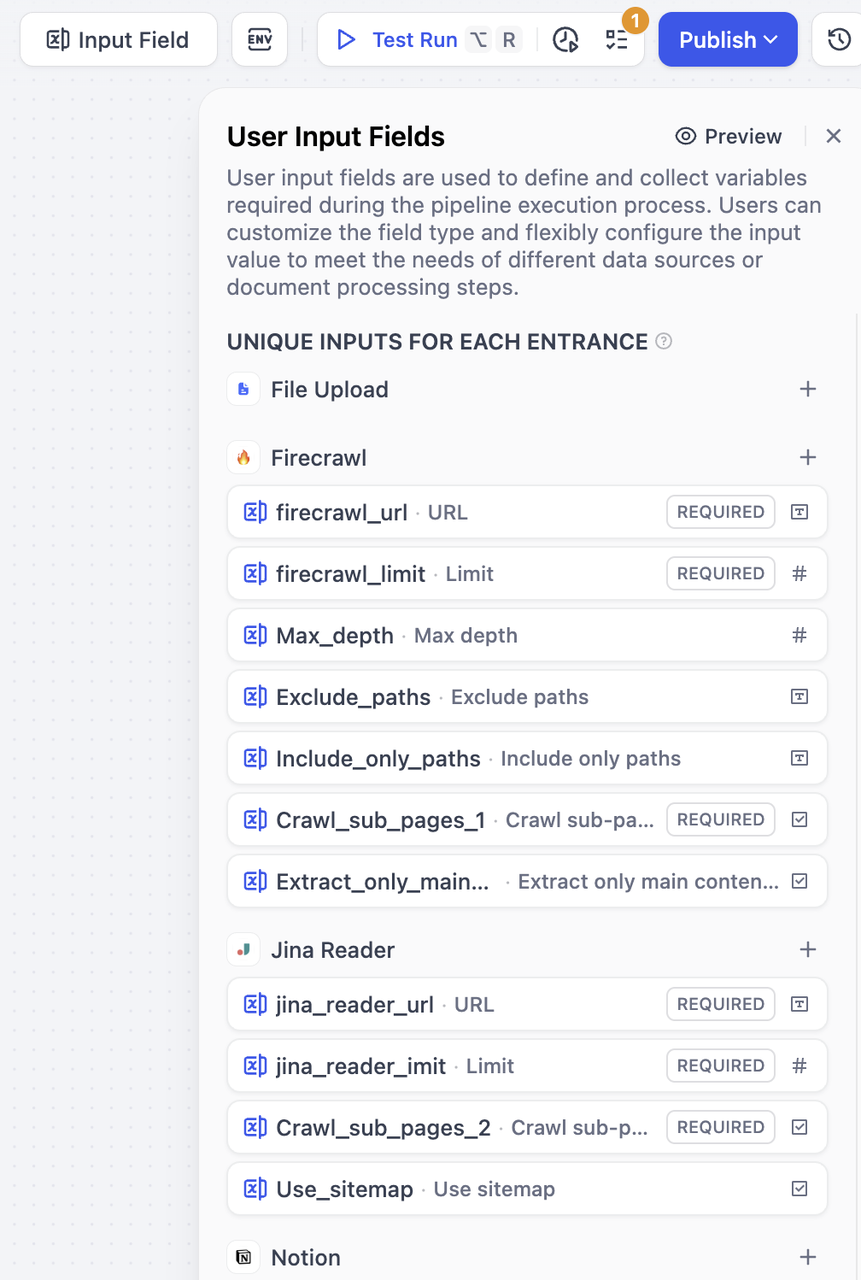
これは各データソースや下流ノードに固有です。該当データソース選択時のみ入力対象となります(例:異なるURLの指定等)。
作成方法:データソース横の+ボタンからそのソース専用フィールドを追加できます。選択したソースからのみアクセス可能です。
すべてのエントランス共通入力¶
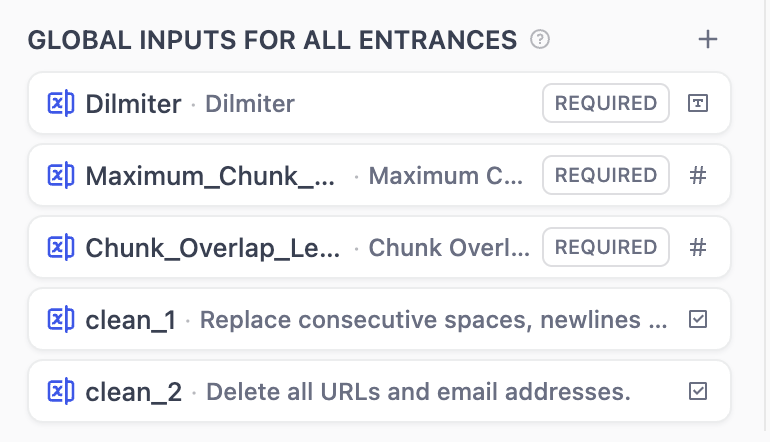
全ノードから参照できるグローバル共有入力です。チャンク区切りや最大長等、汎用パラメータの入力に適します。
作成方法:グローバル入力の+ボタンから追加できます。
サポートされる入力フィールドタイプ¶
ナレッジパイプラインでは7種の入力変数をサポートします:
Warning:
詳細は入力フィールドのドキュメントをご参照ください。
フィールド設定オプション¶
全入力フィールドには必須/任意および追加設定があります。適切なチェックで必須化等を指定します。
| 設定 | 名称 | 説明 | 例 |
|---|---|---|---|
| 必須設定 | 変数名 | 内部識別用(英数字・アンダースコア推奨) | user_email |
| 表示名 | UI上に表示される名称 | ユーザーメール | |
| タイプ固有設定 | タイプごとの条件 | テキストの最大長制限等 | |
| 追加設定 | デフォルト値 | 未入力時の既定値 | 数値は0、テキストは空文字 |
| プレースホルダー | 入力欄が空のときのヒント表示 | 「メールアドレス入力」 | |
| ツールチップ | 補足説明(マウスホバー時表示) | 「有効なメールアドレスを…」 | |
| 特殊任意設定 | タイプごとの特殊バリデーション | メール形式チェック等 |
設定後、右上のプレビューボタンで実際のフォーム動作確認やフィールド並び替えが可能です。「!」マーク表示時は参照無効を示します。
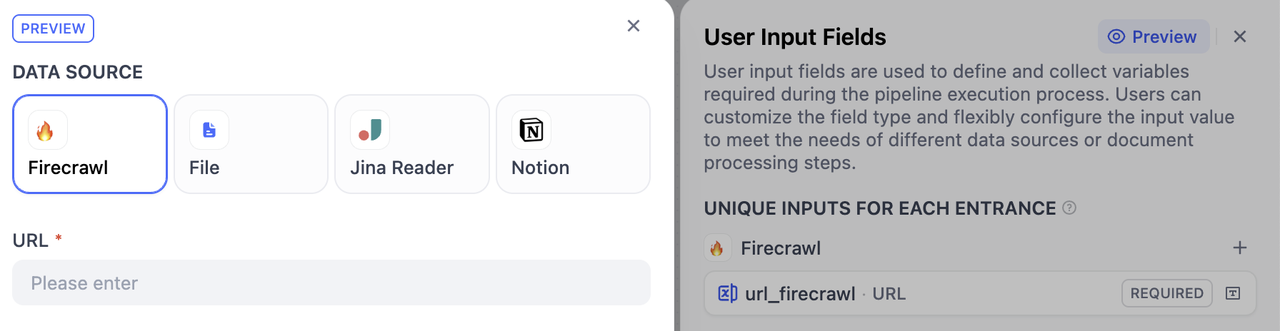
ステップ5:ナレッジベースの命名¶
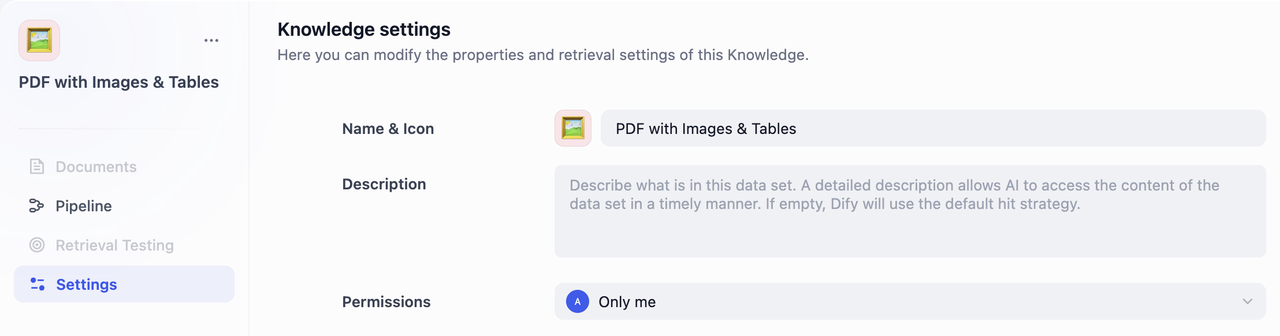
デフォルトのナレッジベース名は「Untitled+番号」、権限は「自分のみ」、アイコンはオレンジ色の書籍です。DSLファイルからインポートした場合は元のアイコンが適用されます。
左パネルの「設定」をクリックし、以下を設定してください。
- 名前とアイコン
ナレッジベース名を決定します。絵文字選択、画像アップロード、画像URLによるアイコン設定が可能です。
- ナレッジベース説明
簡単な説明を記入してください。AIがデータをより適切に理解し検索できるようになります。未入力の場合はFlexAIのデフォルト検索戦略が使われます。
- 権限
ドロップダウンから適切なアクセス権限を選択してください。
ステップ6:テスト¶
いよいよ最終工程です!
設定が整ったら、まずは全設定の完全性チェックを行いましょう。チェックは右上のチェックリストボタンで行え、不足項目があると通知されます。
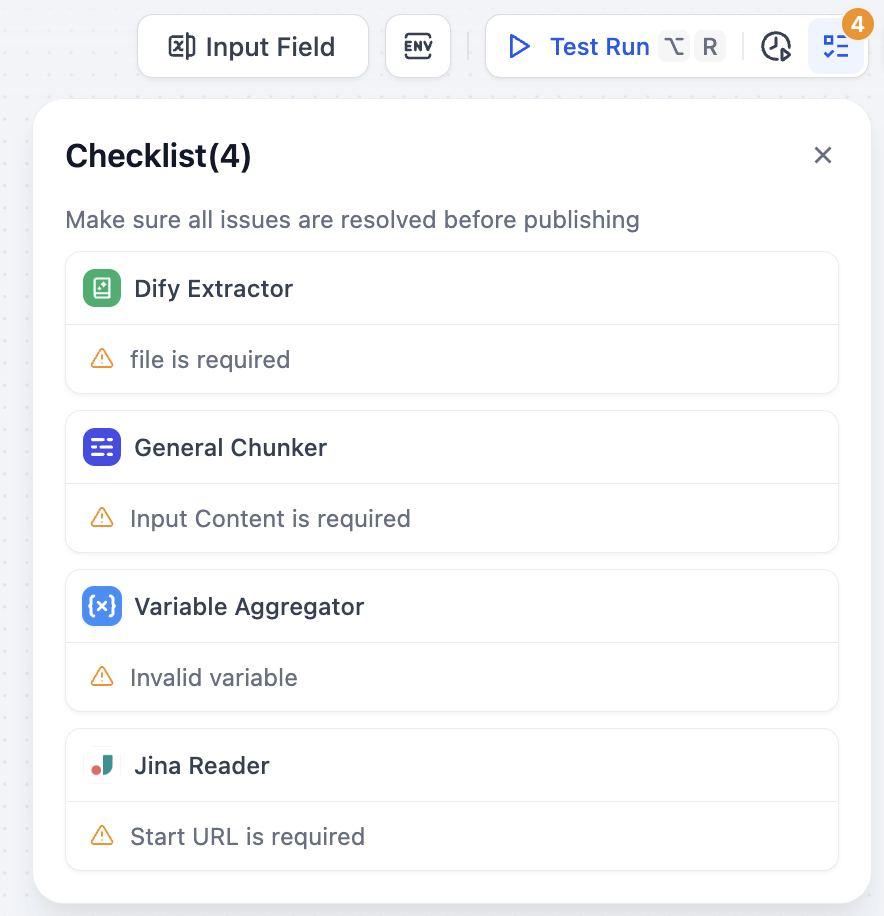
全設定完了後、テスト実行でパイプライン全体の動作確認を行い、不備がないことを確認した上で公開します。
テスト実行¶

- テスト開始:テスト実行をクリック
- テストファイルインポート:右側ウィンドウからファイル選択
Warning:
注意: デバッグのため、1回につき1ファイルのみアップロード可能です。
- パラメータ入力:設定した入力フォームに従い必要なパラメータを入力
- パイプライン実行:次へをクリックしテスト開始
テスト時は、履歴ログ(実行記録の確認)や変数インスペクタ(ノード入出力内容の可視化)が問題特定に役立ちます。